
私の環境(RX 7900XTX)で動かせる中で久々にまともに使える用途があるモデルが来ました。まともなモデルはgpt-ossとこれだけです。Qwen3-30-a3b系はちょっとメモリがギリギリすぎる。

ベンチマークの結果はhuggingfaceのページを見てもらうとして、使ってみた感想をつれづれなるままに書いていきます。
- 日本語がまとも
- Reasoningの内容が正しい
- 長文読解◎
- 簡単なバイブコーディングができる
Qwen3では会話の中で若干簡体字や変な造語が混じることがありましたが、今のところ遭遇していません。
Reasoningの内容が正しいです。小さいモデルにありがちな「挨拶は『こんにちは』でいきます。Wait, 『こんにちは』ではあまりに簡潔すぎます。『こんにちは。何かお手伝いできることはありますか?』いきましょう。Wait, 」みたいなことを何分も考えるといった挙動がありません。

何を聞かれているかを整理する→囚人のジレンマを思い出す→囚人のジレンマとなっている事象をブレストする→選ぶ→説明する
という段階を正しく踏んで答えてくれました。
長文読解も良好です。65000文字くらいの小説を読み込ませて一人の登場人物について説明させたところ、必要十分な文が帰ってきました。
懐かしのClineで「クライアントがjavascriptを実行できない環境で動作するBBSを作ってください。スレッドの管理にはjsonを使ってください。」との文だけ与えてバイブコーディングさせてみたところ、行間を適切に読んでお望みのものを出してくれました。
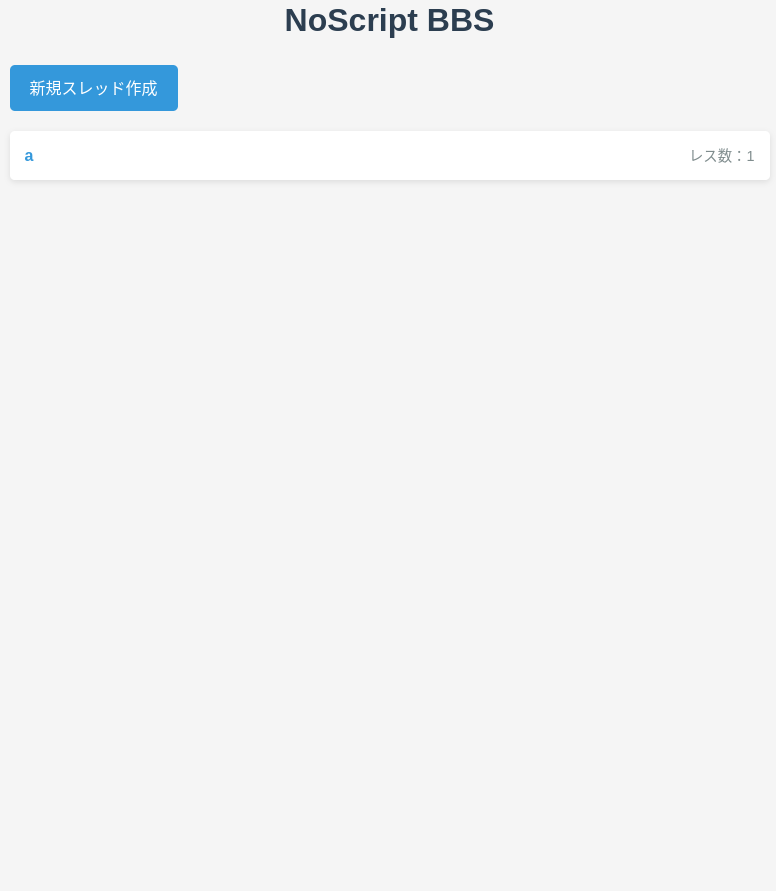
わざわざ言わなくてもスレッドを複数管理できて正常に動作するBBSを作ってくれました。gpt-ossでさえ安定しなかったので、SLMの大きな進歩だと言えます。Qwen3-30-a3b系ではできなかったことができます。22.6kトークンを消費しました。これはQwen3.5 397B A17Bの半分の消費量です。とってもエコ!
少なくともClaude 3.5 Sonnet以上の働きをしてくれます。2024年の終わりにリリースされたプロプライエタリモデルに匹敵する能力ということです。ローカルでバイブコーディングするという夢が実現できるかもしれません(実際にはまだコンテキストウィンドウがRAMを圧迫しすぎる問題があります)。


コメント